← Разработка
Manticore Search в InstantCMS

Знакомьтесь: Manticore Search — текстовый поисковый движок с открытым исходным кодом для фильтрации больших данных и потоков.
1. Фильтрация многоязычных пользовательских потоков данных в режиме реального времени
2. Индексирование и поиск по сотням терабайт данных
3. Результаты поиска группировка и огранка
4. Ранжирование результатов поиска высокого качества...
5. Бэкенд для интерфейса поиска (например, «Вы имели в виду», автозаполнение поисковой фразы, исправление орфографии и т.д.)
Manticore Search родился в 2017 году как продолжение Sphinx Search (которое началось в 2001 году). Мы взяли лучшее из Sphinx (ядро C ++ и сосредоточились на низкоуровневых структурах данных и отлаженных алгоритмах), добавили больше функциональности, исправили тонны ошибок, упростили его использование, сохранили его с открытым исходным кодом и сделали Manticore Search еще более легким и доступным. Очень быстрая полнотекстовая поисковая система.
Пишут авторы на своем сайте: https://manticoresearch.com/about/
Ладно, хороший так хороший. Раз форк Sphinx, то будет проще. Почитал документацию (ее много), и добавил Manticore к InstantCMS — к каталогу.
В общем, почему пишу это? У меня есть в уме, как должен выглядеть тут поиск, но ни один поисковый движок, а я хотел взять готовый и не тратить на него время, его мало, не дает быстро сделать то, что планирую. Простой, чистый, но совмещенный поиск, которые будет на одной странице представлять результаты по статьям, каталогу, тегам, авторам и пространствам одновременно. Он будет учитывать морфологию и т.д.
Поиск на проекте важная часть, и хочется его сделать достойно. Вот и взял, самое простое, но, ИМХО, достаточно универсальное.
Все, перестаю смотреть на разные варианты и начинаю работать с Manticore. Главное сделано — цель определена. )
Сейчас поисковая выдача имеет вид:
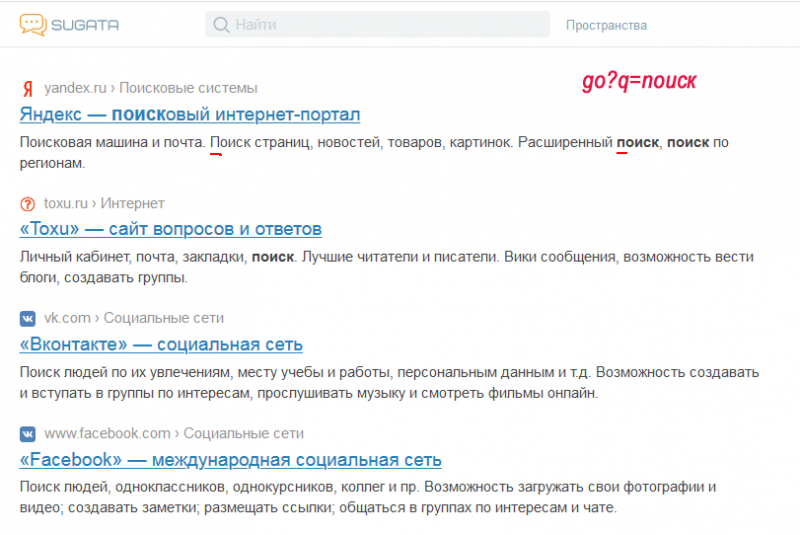
И мы уже можем видеть по скриншоту ошибки. Надо разбираться.
Исходники после того, как закончу отладку будут опубликованы на GitHub… Сделать бы их только максимально универсальными, чтобы они подошли без напильника многим.
Вот еще статья на Хабре: Андрей Карпов считает, что код проекта Manticore качественнее, чем код проекта Sphinx
Сам не читал (только 1 абзац), каюсь.
Не знаю на счет качества (читать буду позже), но выбранный вариант проще, и главное — занимает меньше времени, чем осваивать, например, YACY на Java. YACY хороший поисковый движок, но нужна команда, чтобы работать с ним — раз. А два, он заберет много времени. Все же Sugata не поиск по Интернету, и сейчас нет столько времени, как было ранее.
Начинаем работать с Manticore. )
@n0byk спасибо, что очередной раз напомнил. Действительно, хватить прыгать и искать, надо остановиться на одном и сделать то, что хочется. Поисковый скрипт позволяет.
Первые шаги, пробуем: https://sugata.ru/go?q=cms
Рабочий набросок тут: https://github.com/Toxu-ru/instantcms-manticore

Hacker News на нем — интересно.
Пойду почитаю, что это такое.
В общем вот. Макет того, что удалось сделать за сегодня, ссылку разместил в конце поста.
Далее настраивать. Неожиданно столкнулся с трудностью установки. 57 релизов под разную ОС. Какой выбрать? Чуток ошибся, пришлось переставлять. Документацию надо читать было сразу.
Далее делать, настраивать, переставлять, пересобирать чтобы сделать так, как я вижу этот самый поиск. Словари не все работают, причина — кодировка, она известная. Locale — смотреть надо. Подсветка, вводить другие секции, статистику, подсказки… В общем, это на долго ковыряться.
Сайтов мало. Надо довести их до 1000. За пару дней из нашей базы их добавлю. Тем более, категория Товары и услуги пуста, а она самая большая. Сейчас смотрю, там более 1800 сайтов.
Это да. Надо добить. Подключил еще один индекс, натравив на категории и вывел их сбоку. Сейчас есть кроме ленты 2 подсказки. Словарь синонимов мне нужен, скиньте плиз.
Прочитал. А зачем мы вообще используем обращение через cms? Мы можем создать в индексах те поля, что нам надо и брать 100% от туда. Мне кажется, это более логичный вариант.
Мы вообще не совсем верно все сделали. Мы используем поиск для получения лишь уникального id документа.
И все. Имея id мы получаем значение уже из cms. А действительно, а зачем нам sql выборка лишняя? Мы можем все получить, что хотим средствами самого поиска. Переписать конфиг индексатора, добавить поля нужные и все. Сейчас переделаю. Пусть поиск и внутренние алгоритмы все и делают. Раз мы уж его подключили, то пусть его ядро и работает. А чё. А то я смотрю, индексы какие-то странные. Правильно, там id и еще некоторая служебная инфа записана и усе. Если мы так сделаем, время поиска убирать надо. А смысл его показывать? Сейчас 0.001 там это с учетом php. А там его не будет. Так чего показывать 0.
Можно не убирать. Мы покажем время с учетом боковых подсказок.
Будут вопросы — будем рады помочь:
* в слаке — https://slack.manticoresearch.com/
* на форуме — https://forum.manticoresearch.com/
По подсветке: возможно charset_table нужно подкрутить, чтоб П преобразовывалось в п.
Команда Manticore Search.
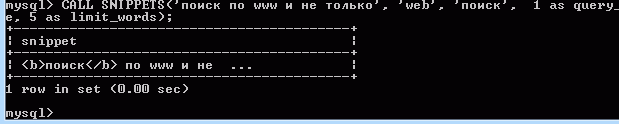
Спасибо, вопрос с подсветкой решен. Это была наша ошибка. SNIPPET из коробки работает прекрасно.
Добавил вывод и по комментариям. Может быть этот индекс стоит настроить как-то по другому. Словари там отключить, или еще что, чтобы был другой вывод. Или с ранжирование поиграться.
Вышла новая версия сегодня. Есть какие-то важные изменения?
Детали, например: fix, использовании сегментов оперативной памяти индекса RT с параллельной вставкой и т.д. Там можно глянуть по комментам, например. Тут обновил уже.
Значительней лучше ищет родного.
Так… десятки мегов C++ брошены только на поиск. Специализация это называется. Объем поиска больше чем весь тут движок.