← Разработка
Будьте осторожны с «большими данными» oc
Я начал вспоминать работу с данными, перечитывать различные исторчники, например, Ricardo Galli, чтобы лучше понимать то, что мы пытаемся сделать.
В последнее время много говорят о больших данных, они даже родили или помогли создать ажиотаж 2013 года: Data Journalism. В этом нет ничего нового, крупные корпорации десятилетиями проводят такой анализ, также известный как «извлечение данных» или «перспективный анализ». На Уолл-стрит были известны очень сложный «анализ 4:15», уже очень давно.
В последние годы большие данные стали популярными, у нас появилось больше доступных данных, их проще получить, а также значительно проще и дешевле получить необходимую вычислительную обработку. Проблема с большими данными состоит в том, что очень трудно отделить шум от сигнала, если вы не очень осторожны.
Давайте перейдем к конкретному примеру. Предположим, у нас есть только следующие данные об эволюции некоторых экономических или социальных показателей за последние 40 лет (во многих исследованиях используются только последние 20 лет):
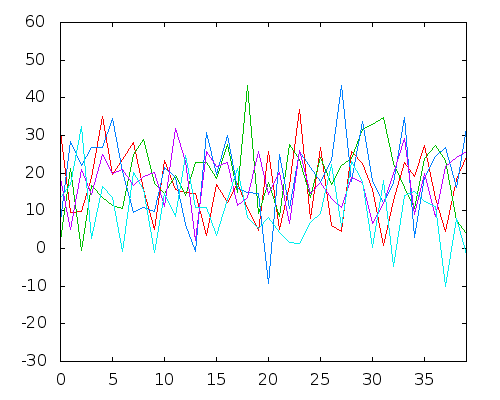
Переменные с 1 по 5
Эти данные не говорят много, на самом деле, если использовать инструменты статистической корреляции, почти ничего не будет найдено.
Теперь предположим, что вместо пяти переменных у нас есть тысяча доступных переменных, которые уже выглядят как большие данные!
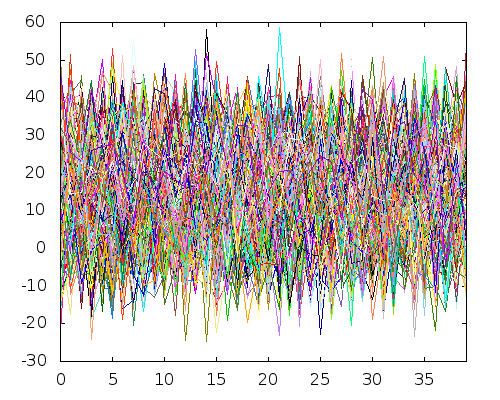
1000 переменных
С помощью этих данных корреляции между переменными могут быть получены с использованием таких алгоритмов, как, например, Пирсон. Мы получили бы интересную информацию, например, что есть пара переменных, которые имеют высокую положительную корреляцию (то есть они растут или уменьшаются вместе):
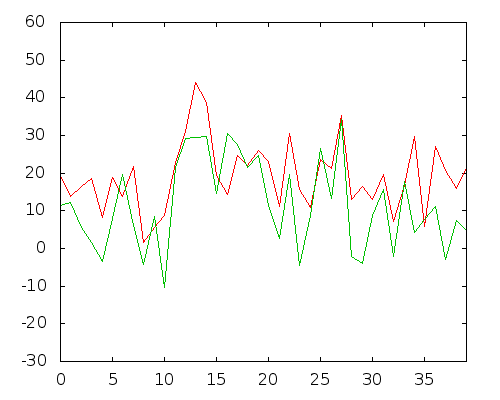
Переменные 30 и 132, корреляция Пирсона: 0,66
Это не может быть совпадением, верно? Между ними существует очень четкая взаимосвязь. Если проанализировать немного больше, мы найдем несколько пар переменных с очень похожей эволюцией.
Мы могли бы даже найти переменные с отрицательной корреляцией:
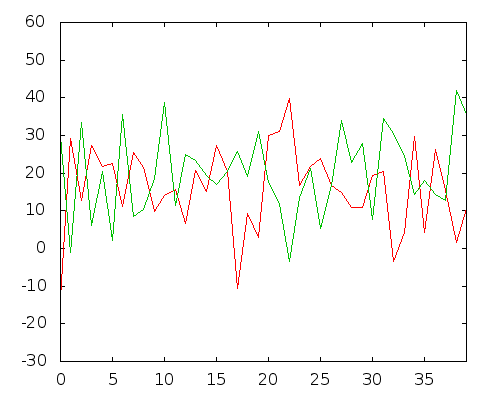
Переменные 49 и 570, корреляция Пирсона: -0,64
Очень хорошо, алгоритмы и инструменты (даже электронные таблицы) обнаружат эти корреляции, и мы можем начать обнаруживать интересные вещи, которые мы не знали раньше.
Но есть большая проблема. Те 1000 переменных с 40 значениями являются чистым шумом. Я сгенерировал их с помощью программы с псевдослучайными числами. Если бы вместо 40 значений (или «лет») использовалось только 20, найденные корреляции были бы еще выше.
В этих случаях только здравый смысл — может исключить случайные корреляции. Еще хуже, когда данных много, очень трудно отделить шум от сигнала. Каждый день мы будем видеть все больше графиков и анализов такого типа, абсолютно бесполезных, которые в некоторых случаях могут привести к катастрофическим последствиям, если они не будут тщательно проанализированы.
Наше общество очень сложное, генерируется много данных, но большинство из них — шум или мусор. Кроме того, как объясняет Талеб, использование этих сложных анализов сделает наше общество еще более сложным, поэтому, возможно, мы никогда не поймем полностью, как мы функционируем.
Так что будьте бдительны, вы должны быть очень осторожны при проведении анализа, и скептики не верят тем исследованиям больших данных, которые становятся все более популярными. Это не так просто, как знать, как использовать статистическую программу или электронную таблицу, требуется много навыков и статистических знаний, чтобы быть минимально уверенными в том, что никакая ненужная информация не встаивается.
Если вы видите красивые графики, будьте скептичны.
А теперь о более приземленном. Мы заказали взлом, не этого сайта, но копии,в течении следующих 10 дней. 2 независимые хакерские атаки будут проведены с анализом кода в это время.

Анализ данных — не мой конек, точно. По поводу взлома — да, потираю руки и жду с нетерпением.
Не буду создавать еще один пост, посему тут: у нас образовалась пауза, до начала следующей недели — точно (я уехал). И мы можем потихоньку начать работать с комментариями. Выделение лучших — готово, теперь можно перенести популярных авторов в верхний уровень, как мы это делаем тут:
И как работает это тут:
И предпринять слабую попытку компенсировать хаотичность дерева. Хотя по словам Джеффа Эдвуда, это бесполезно. Посмотрим. Это не обязательно делать, но проанализировать точно стоит. Я до сих пор в некотором замешательстве от смешивания моделей: дерево — для дискуссий, плоский — для Q&A. Какой-то бардак. А данные, они пусть пишутся. Есть данные, есть работа. )
А данные, они пусть пишутся. Есть данные, есть работа. )
Готово. Аудит сайта прошел. Есть 2 недочета (не критические). Один подправил уже (с menu).
На самом деле, и их можно сказать нет. Отладка стоит. Там бы и пути не показал бы.